Introduction: The Great Friction
Let's talk about friction..
Right now, we are in the middle of a remarkable technological shift, but progress is being held hostage by a small, technical detail, a detail that is costing us time, creativity, and billions in wasted computation.
You've done the work. You’ve taken a powerful generalist model, like a Llama, and you’ve fine-tuned it into a true expert, a financial analyst, a pitch-deck writer, a customer service genius. You didn't train the whole massive brain; you created a small, efficient skill package called a LoRA adapter, we call it a "Domain Cartridge”. This Cartridge is the crown jewel of your investment.
Then, the inevitable happens. A better model arrives: faster, smarter, more efficient. Maybe it's a Mistral or something new entirely. And suddenly, your crown jewel, your hard-won expertise, is locked in.
Why? Because your Llama-trained adapter is custom-fit to the internal geometry of Llama's brain. The dimensional space, the way Llama processes a thought: it’s unique. Trying to run that specialized skill on a new architecture is like trying to use a PlayStation game in an Xbox slot. It just doesn’t fit.
You face the impossible choice: Stick with the obsolete, or start from scratch. Retrain. Spend weeks, millions of dollars in compute, and hope you still have access to that original, often proprietary, training data. This friction is a tax on every moment of enterprise innovation. It’s what stops adoption cold.
Retrain or Stagnate: You've perfected a specialized AI skill (a LoRA adapter) for a model like Llama. When a better model like Mistral arrives, your valuable work is incompatible.
The Solution: A Universal Translator
What if we didn’t have to retrain? What if we could simply move that expert skill, instantly, cheaply, and with zero loss of knowledge?
This is the problem we set out to solve. And our answer is the Activation Space Mapper (ASM).
The core concept is this: We don’t retrain the skill; we only train the translator.
We treat the original, specialized Cartridge as a perfect, unchangeable behavioral specification. It is the instruction set. It is the truth. We freeze it. We don't touch it.
Instead, we teach the new model, the target, how to understand the language of the old, source model.
Imagine the specialized Cartridge writes instructions in a unique dialect. The ASM creates a seamless, bidirectional glossary.
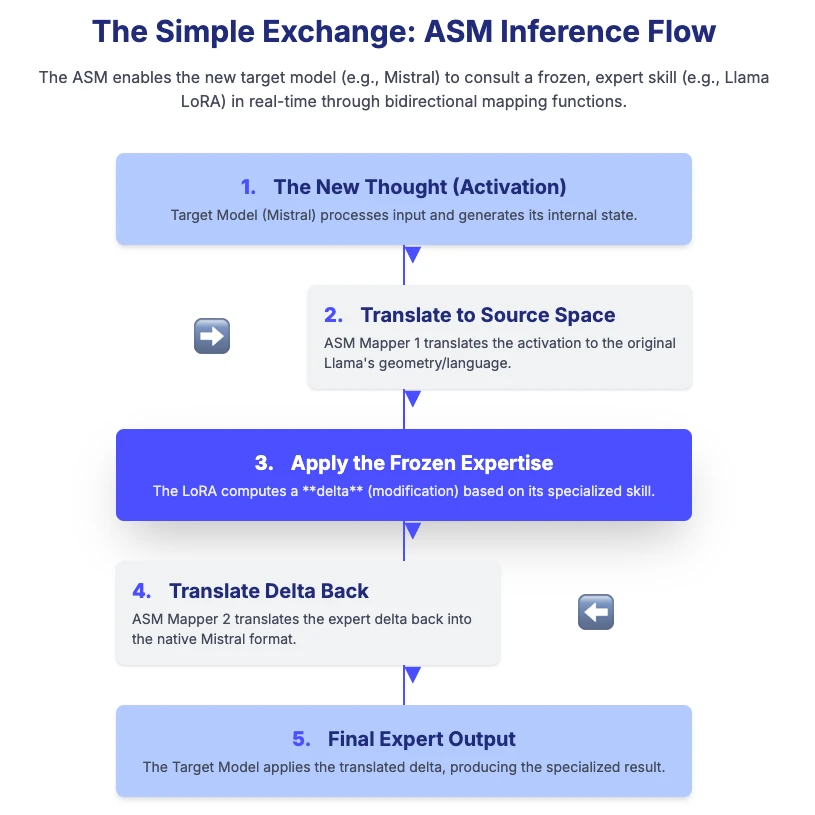
- The New Thought: The new, powerful target model processes an input and generates an internal thought, what engineers call an activation.
- Translate to Source: The ASM uses a small, lightweight “mapper” to instantly translate that thought into the geometric language, the activation space, of the original source model.
- Apply the Expertise: Now that the thought is in a format the frozen Cartridge can understand, the Cartridge applies its logic. It computes a delta, a precise, tiny modification that represents the expert skill.
- Translate Back to Target: A second ASM mapper takes this expert delta and instantly translates it back into the native language of the new, powerful target model.
- Final Output: The target model applies this translated delta and produces the specialized, expert-level output.
This entire process is about training two tiny translation functions. The expert knowledge is perfectly preserved, and it’s now instantly portable.
Training: The Elegant Mimicry
The genius of ASM is in what we don't need. We don't need your proprietary financial data, your customer logs, or your creative writing portfolio. We don't need to teach the model how to be an expert all over again.
We only need to teach the new model how to mimic the behavior of the old model.
We achieve this with an elegant form of knowledge distillation, leveraging a vast, general corpus of text—like filtered Wikipedia.

We use two models, in a Teacher/Student relationship:
- The Teacher: The original source model with the frozen, expert Cartridge attached.
- The Student: The new target model equipped with the trainable ASM mappers.
We train the ASM mappers to align these two models using two critical objectives:
- External Alignment (Output): We make sure the Student learns to predict the exact same next words as the Teacher. This guarantees the external behavior is identical.
- Internal Alignment (Thought): We also compare the deep, internal states of both models. This forces the ASM mappers to make the internal thought processes geometrically similar.
By aligning both the speech and the thought of the two architectures, the ASM mappers learn to seamlessly bridge the architectural gap. And because these mappers are minuscule compared to the Cartridge itself, this training is blisteringly fast and computationally cheap.
ASM mappers are trained using a Teacher/Student relationship and a general text corpus to learn the behavioral bridge, aligning both the model's speech and thought.
The Frictionless Impact
So, what does this translation capability actually unlock? The results are not just promising; they are foundational.
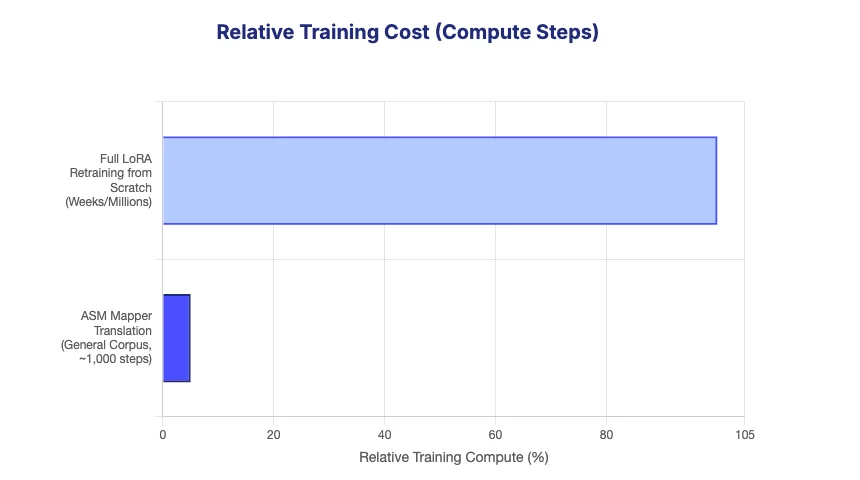
In our flagship experiment, translating a specialized Cartridge from Llama-2-7B to Mistral-7B, two distinctly different brains, the ASM-translated adapter achieved 85% to 95% of the performance of a brand-new Cartridge that was fully retrained from scratch.
We achieved this fidelity in performance with just 1,000 training steps and at a tiny fraction of the energy cost.
The implications for enterprise adoption are profound:
- Agile Migration: You can immediately upgrade your specialized AI to the latest and greatest base models the moment they hit the market, without the retraining headache. Your specialized skill is now future-proof.
- Hardware Optimization: Train your expert skill once on a powerful, massive model, and then use ASM to translate and deploy it instantly to a smaller, hyper-efficient model for inference on edge devices or in high-volume, cost-sensitive environments.
- Rapid Prototyping and Research: Researchers and product teams can now study how a single learned skill works across dozens of different architectures from a single initial training run, accelerating discovery.
Conclusion: Decoupling Skill from Architecture
The Activation Space Mapper is more than just a migration tool. It’s a philosophy. It’s the tool that decouples a learned skill from its underlying model architecture. It makes specialized knowledge portable, flexible, and accessible.
We are taking the step from siloed systems to an interoperable, efficient AI ecosystem. Your skill is no longer locked in; it is free to move.
Our work is open-source. The code, the documentation, and the examples are available now. This isn't a secret handshake; this is a movement.
We’ve built the map. We invite you to begin the journey.