


The foundational Large Language Model (LLM) revolution is upon us, but if you're like me, you’re already asking: What comes next? How do we evolve our generalist models into agile, specialized experts without the prohibitive cost of continuous, full fine-tuning?
We stand at the precipice of a new paradigm, and its closest analogue isn't found in a textbook, it's found in cinema.
Imagine Neo in The Matrix, needing to learn a new skill. He doesn't read a manual; he sits down, and Tank instantly uploads a "Kung Fu" cartridge directly into his mind. Suddenly, the skill is innate, not contextual.
This is the essence of Retrieval-Augmented Parameterization (RAP), a state-of-the-art innovation that moves beyond simple Retrieval-Augmented Generation (RAG). With RAP, we are no longer feeding the LLM notes; we are instantly uploading specialized knowledge directly into its parametric core.
The Architectural Leap: From Reading Notes to Uploading Skills
For years, the standard solution for domain expertise was RAG. RAG is highly effective for fact-checking: a retriever pulls relevant text (e.g., a financial report) and gives it to the LLM as temporary context. The model reads the notes and generates a response. Crucially, RAG does not fundamentally alter the model's deep-seated parametric knowledge or imbue it with new reasoning patterns.
RAP flips this script. Our Domain Cartridge system retrieves specialized model parameters, not text, and instantly modifies the LLM's intrinsic behavior.
This isn't augmentation; it’s an agile, on-demand transformation into a genuine expert.
The Four Pillars of Dynamic Specialization
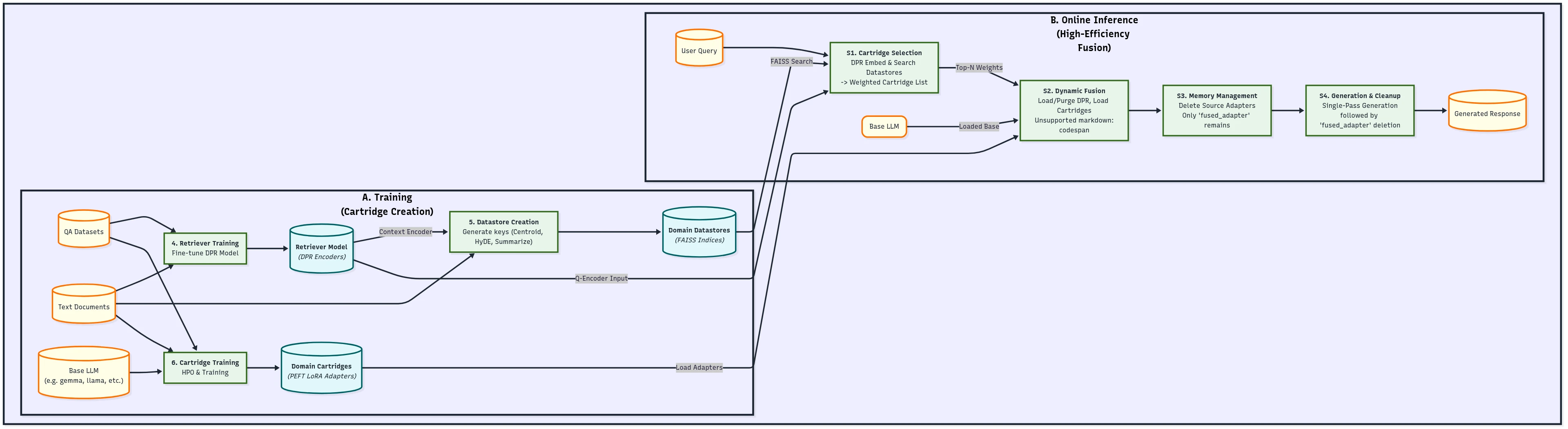
Our architecture achieves this instantaneous transformation through four core components, which function as the hardware and software for our “skill upload” system:
- The Base Language Model (The Brain): This is the frozen, general-purpose intelligence (like a 4-bit quantized model) that provides foundational reasoning and linguistic structure. It is the stable consciousness, ready to receive new skills.
- Domain Cartridges (The Skill Files): These are modular, lightweight, and exchangeable PEFT LoRA adapters. Each cartridge is a highly refined expert: a "Law Cartridge" a "Biotech Cartridge" or a "Manufacturing Cartridge", crafted through an automated hyperparameter optimization pipeline to ensure peak performance for its niche.
- The Cartridge Retriever (The Intelligent Selector): This fine-tuned DPR model instantly analyzes the user's query and identifies the necessary expertise. If the query spans corporate finance and regulatory law, the retriever identifies and weights both the Finance and Law cartridges. It uses advanced techniques like Hypothetical Document Embeddings (HyDE) to ensure robust semantic matching of user intent.
- High-Efficiency Fusion-Generation Engine (The Upload Console): This is the core magic, the performance engine that orchestrates the instantaneous download and cleanup.
RAP moves beyond simple document retrieval (RAG) and uses lightweight, modular "Domain Cartridges" to instantly and dynamically inject specialized knowledge directly into the LLM's core parameters. Our breakthrough Fusion-Generation Engine selects the necessary expert cartridges (e.g., Law + Finance), seamlessly merges them into a single adapter, and generates an interdisciplinary response in one high-speed pass.
The Quantum of Performance: Single-Pass Fusion
The most innovative component is the Fusion-Generation Engine, which eliminates the primary performance bottleneck that plagues multi-adapter systems: latency.
For every query, a precise, memory-managed workflow is executed:
- Selection & Swap: The most relevant cartridges (e.g., A and B) are identified and weighted. Crucially, the powerful Cartridge Retriever model is immediately purged from memory to make space for the expertise.
- Load & Fuse (The Matrix Moment): The required cartridges are loaded. The High-Efficiency Fusion engine then dynamically merges the separate expertise modules (A and B) into a single, temporary, composite cartridge (the "fused_adapter"). This merging uses sophisticated techniques (like TIES merging) to intelligently blend skills, even if the source cartridges have different technical ranks.
- Deletion & Generation: The moment the fusion is complete, the original source cartridges are immediately deleted from VRAM to conserve resources.What remains is the base LLM and one single, unified "fused_adapter." The model then generates the response in a single forward pass per token.
- Cleanup: Once the response is delivered, the temporary "fused_adapter" is also deleted, ensuring the system is clean and stateless for the next query.
This high-efficiency, single-pass fusion design delivers rapid, specialized intelligence without the "prohibitive latency" of costly multi-model approaches, which is the necessary prerequisite for scalable, commercial AI agents.
The Value Proposition: True Multi-Domain Synthesis
The result is an AI capable of True Multi-Domain Synthesis.
When a query requires expertise from two or three separate fields, for instance: "Analyze the financial impact of a new EPA regulation on a manufacturing supply chain", a single expert model or standard RAG cannot deliver a nuanced answer. RAP, by dynamically fusing the Finance Cartridge, the Law Cartridge, and the Manufacturing Cartridge, creates a temporary, hyper-specialized expert capable of generating a complex, interdisciplinary response.
The Domain Cartridge system is a scalable, modular solution for dynamic LLM specialization. It’s the next paradigm for AI, moving us from general intelligence that merely reads documents to agile intelligence that uploads skills on demand.
Ready to Build the AI of Tomorrow?





